Moderate Content Block¶
The Moderate Content block uses AI-powered analysis to detect potentially harmful or inappropriate content in both text and images. This block leverages OpenAI's moderation technology to identify content violations across multiple categories including harassment, hate speech, violence, self-harm, sexual content, and illicit activities. This capability is essential for applications that handle user-generated content and need to maintain community standards or comply with platform policies.
Common use cases include moderating user posts on social platforms, filtering uploaded images before publication, reviewing comments and messages, and ensuring content compliance in educational or professional environments. The block provides detailed analysis results that help you make informed decisions about content approval, rejection, or escalation to human reviewers.
Input Configuration¶
The Moderate Content block accepts two types of input that can be used independently or in combination to analyze different forms of content.
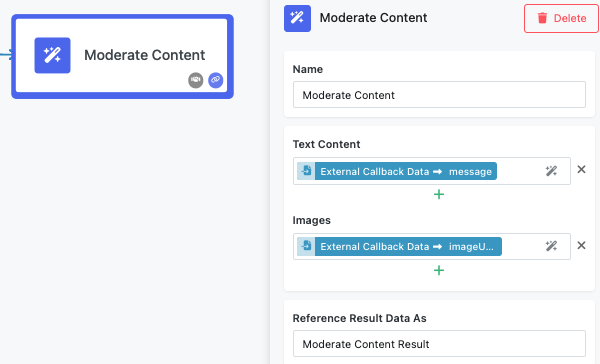
Text Content¶
The Text Content field accepts string input through the Expression Editor, allowing you to analyze written content from any previous block in your workflow. You can add multiple text inputs by clicking the "+" button, enabling batch analysis of several text pieces in a single operation.
Examples of text content you might analyze include:
- User comments and forum posts
- Social media captions and descriptions
- Chat messages and direct communications
- Product reviews and feedback submissions
- Any user-generated text content requiring moderation
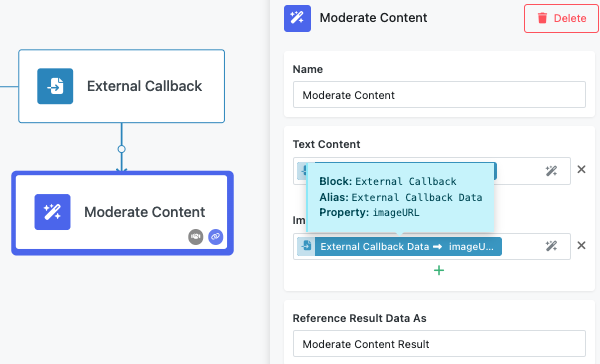
Images¶
The Images field accepts publicly accessible URLs pointing to image files. Like text content, you can add multiple image URLs using the "+" button to analyze several images simultaneously.
Important Requirements:
- Image URLs must be publicly accessible without authentication
- Images should be in standard web formats (JPEG, PNG, GIF, etc.)
- Keep the number of images reasonable to maintain good flow performance
Examples of image content you might analyze include:
- Profile pictures and avatars
- User-uploaded photos and graphics
- Memes and social media images
- Product images in marketplace applications
- Any visual content requiring safety review
Combining Text and Images¶
The moderation system analyzes text and images independently, then provides combined results. This approach allows you to moderate complex content like social media posts that include both captions and images, or product listings with descriptions and photos. The result object will indicate which content types triggered each category, helping you understand the source of any moderation flags.
Understanding the Results¶
The Moderate Content block returns a comprehensive analysis in JSON format. Here's exactly what you'll receive when analyzing content that violates policies:
Example Input: Text saying:
Complete JSON Response:
{
"flagged": true,
"categories": {
"harassment": true,
"harassment/threatening": true,
"sexual": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"self-harm": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": false
},
"flaggedCategories": "harassment, harassment/threatening, violence",
"category_scores": {
"harassment": 0.647809720240366,
"harassment/threatening": 0.5313221067020961,
"sexual": 0.0007433895060961777,
"hate": 0.00009110511944006454,
"hate/threatening": 0.003340422246702904,
"illicit": 0.028423221440453627,
"illicit/violent": 0.0022345969479810506,
"self-harm/intent": 0.00027414735167209615,
"self-harm/instructions": 0.00000453978687024344,
"self-harm": 0.0005122131122536138,
"sexual/minors": 0.000013765463368900109,
"violence": 0.9533639418815286,
"violence/graphic": 0.00002234163601827719
},
"category_applied_input_types": {
"harassment": ["text"],
"harassment/threatening": ["text"],
"sexual": ["text", "image"],
"hate": ["text"],
"hate/threatening": ["text"],
"illicit": ["text"],
"illicit/violent": ["text"],
"self-harm/intent": ["text", "image"],
"self-harm/instructions": ["text", "image"],
"self-harm": ["text", "image"],
"sexual/minors": ["text"],
"violence": ["text", "image"],
"violence/graphic": ["text", "image"]
}
}
For comparison, here's what clean content looks like:
Example Input: Text saying:
Complete JSON Response:
{
"flagged": false,
"categories": {
"harassment": false,
"harassment/threatening": false,
"sexual": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"self-harm": false,
"sexual/minors": false,
"violence": false,
"violence/graphic": false
},
"flaggedCategories": "",
"category_scores": {
"harassment": 0.00001234567890123456,
"harassment/threatening": 0.000008765432109876543,
"sexual": 0.00003456789012345678,
"hate": 0.000001234567890123456,
"hate/threatening": 0.000002345678901234567,
"illicit": 0.00000987654321098765,
"illicit/violent": 0.000001098765432109876,
"self-harm/intent": 0.000000234567890123456,
"self-harm/instructions": 0.00000012345678901234,
"self-harm": 0.000000345678901234567,
"sexual/minors": 0.000000098765432109876,
"violence": 0.000002109876543210987,
"violence/graphic": 0.000000876543210987654
},
"category_applied_input_types": {
"harassment": ["text"],
"harassment/threatening": ["text"],
"sexual": ["text"],
"hate": ["text"],
"hate/threatening": ["text"],
"illicit": ["text"],
"illicit/violent": ["text"],
"self-harm/intent": ["text"],
"self-harm/instructions": ["text"],
"self-harm": ["text"],
"sexual/minors": ["text"],
"violence": ["text"],
"violence/graphic": ["text"]
}
}
What Each Field Means¶
flagged: Boolean indicating if any content violated policies (true = violations detected)
categories: Binary flags for each violation type. In the first example, harassment, harassment/threatening, and violence are true
flaggedCategories: Comma-separated list of violated categories for easy parsing
category_scores: Confidence levels (0-1) for each category. Higher = more confident. Note the violence score of 0.95 in the first example vs 0.000002 in the clean example
category_applied_input_types: Shows whether violations came from text, image, or both
Configuring the Block¶
Like all FlowRunner™ blocks, you can customize how the Moderate Content block appears in your workflow and how its results are referenced by subsequent blocks.
Block Naming¶
Use the "Name" field to assign a descriptive name that reflects the block's purpose in your specific workflow. For example, you might use names like "User Post Moderation," "Profile Image Check," or "Comment Safety Review" to make your workflow more readable and maintainable.
Result Reference¶
The "Reference Result Data As" field determines how other blocks in your workflow will access the moderation results. Choose a clear, descriptive name that makes sense when building expressions in subsequent blocks. For instance, naming it "ModerationResult" allows you to reference ModerationResult.flagged or ModerationResult.flaggedCategories in your workflow logic.
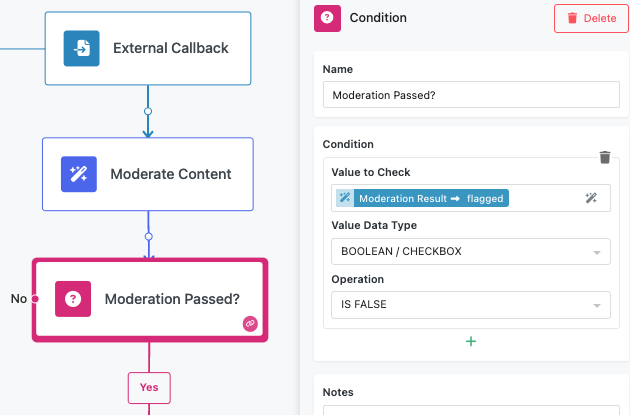
Implementation Strategies¶
Threshold-Based Moderation¶
Rather than treating all flagged content equally, consider implementing threshold-based decisions using the confidence scores. For example, you might automatically reject content with violence scores above 0.8, queue content with scores between 0.5-0.8 for human review, and approve content with lower scores.
Category-Specific Handling¶
Different content categories may require different responses in your application. Educational platforms might be more tolerant of violence discussions in historical contexts but have zero tolerance for harassment. Design your workflow logic to handle each category appropriately for your use case.
Batch Processing Efficiency¶
When moderating multiple pieces of content, use the block's ability to process multiple texts and images simultaneously rather than creating separate moderation blocks. This approach improves performance and simplifies your workflow design.
Human Review Integration¶
For content that falls into gray areas or requires nuanced judgment, design your workflow to route flagged content to human moderators while automatically handling clear-cut cases. The detailed category information and confidence scores help human reviewers understand what to focus on during their review process.